PAULA DOLORES RESCALA

Data Scientist with 3+ years of hands-on experience specializing in machine learning, natural language processing, and computer vision, developed through internships, academic research, and a comprehensive Master's thesis. Proven track record of delivering high-impact solutions, including developing state-of-the-art models and deploying end-to-end machine learning applications. Adept at leading Agile teams, with a strong foundation in Python, cloud platforms, and advanced data science techniques. Passionate about leveraging data to drive innovation and solve complex problems.
Feel free to connect with me or check out my socials below if you have any comments, questions, or are looking to expand your network! I am open to work!






Full resume here.
DATA SCIENCE PORTFOLIO
Projects
Book Review Reviewer (BR2): Predicting Book Review Engagement from Readers Users on Goodreads
I’ve always loved reading, and to make the most out of it (and for fun), I started writing reviews on Goodreads. Wanting to boost engagement, I decided to dive into the data and see what makes a review popular. In this project, I used feature engineering on text data to build a classification model that predicts how well a review will do based on votes. I even built a website where I can run my reviews through the model and tweak them for better results. Feel free to try out the tool yourself!
Data Format: Text
Skills Utilized: Natural Language Processing (spaCy and TextBlob), Machine Learning (Classification Models from scikit-learn library)
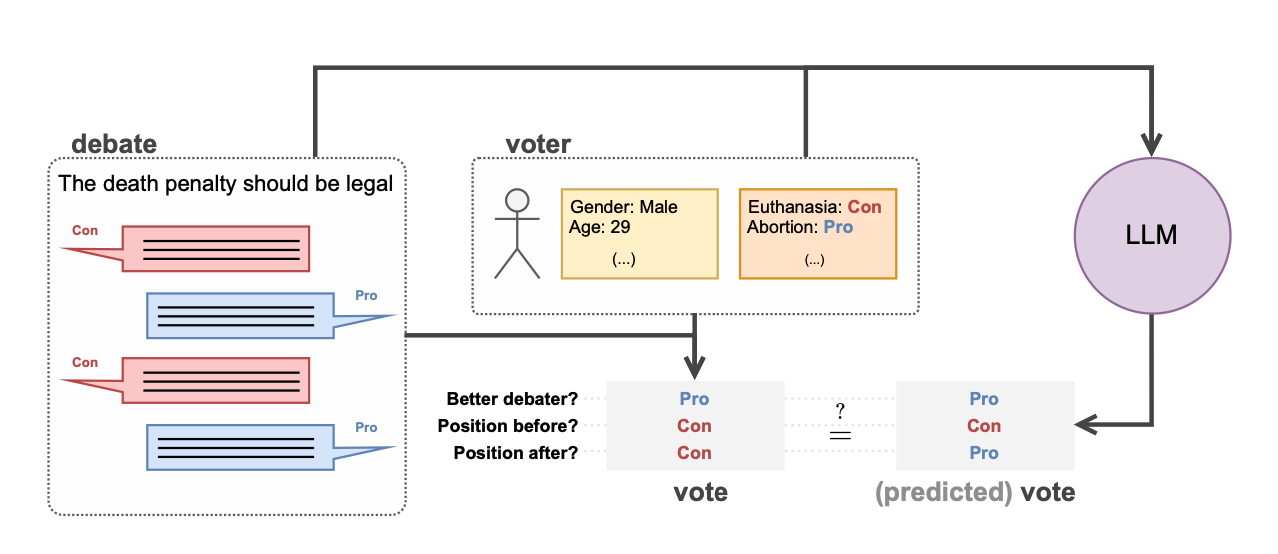
LLMs Can’t Understand What They Generate Pt. 21856238756701???
With the rapid growth of Large Language Models (LLMs), concerns have emerged about their potential misuse for spreading personalized misinformation. To explore how persuasive these models can be, I focused on studying their ability to detect convincing arguments. I extended an existing dataset with debates, votes, and user traits and created tasks for LLMs to (1) distinguish strong arguments from weak ones, (2) predict stances based on beliefs and demographics, and (3) assess how appealing an argument is to someone based on their traits. Surprisingly, LLMs performed on par with humans, and combining outputs from different models even led to better-than-human results. This project contributes valuable data and code to help keep tabs on the evolving capabilities of LLMs.
Indoor Navigation System to Improve Elevator Accessibility for the Visually Impaired
In this project, I explored indoor localization using machine learning to work around the limitations of GPS inside buildings. I collected a unique dataset with thousands of Bluetooth and LoRa measurements and built a Bayesian deep learning model that handles uncertainty in the data. My model boosts accuracy even when the number of beacons is low, making it a practical solution for real-world applications. Plus, it can predict when the data might not lead to the best results, giving users a heads-up when things might get tricky.
Note: code is currently closed-source while we work on publication.
A Human-Centered Approach to Understanding Local News Consumption
This project aimed to understand the news consumption habits of the migrant community and whether their needs are being met by local news platforms. I web scraped over 2,600 articles from a local news site and used natural language processing techniques, including topic modeling, information retrieval, sentiment analysis, and text readability analysis, to analyze the content. These analyses were guided by insights from a focus group with French-speaking migrants in Lausanne. The project combines qualitative insights with advanced NLP techniques to bridge the gap between the news content provided and the needs of its readers.
Certifications
Completed
In progress
- AWS Certified Machine Learning - Specialty
- Tableau Certified Data Analyst